
金色财经报道,OpenAI开源了一个专门面向医疗大模型的测试评估集——HealthBench。与以往测试集不同的是,该测试集的5000段核心测试对话,全部由来自60个国家/地区的26个专业262名医生打造,极大增强了该测试集的难度、真实性以及丰富度。并且采用了多轮对话测试,而不是简单的答题或选择题模式。根据测试数据显示,大模型在医疗保健领域的表现有了显著提升。例如,从之前的GPT-3.5Turbo...
 利好
利好
 利空
利空

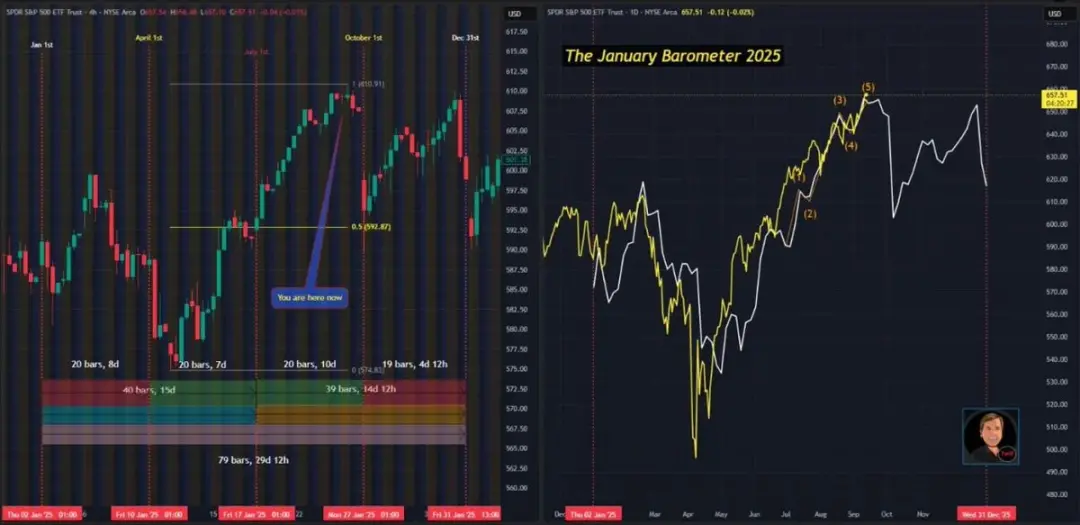
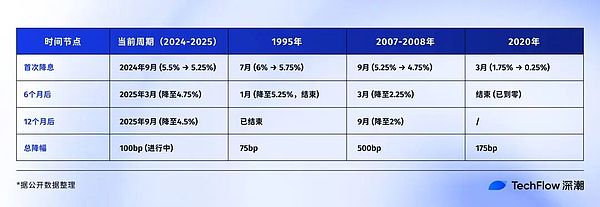

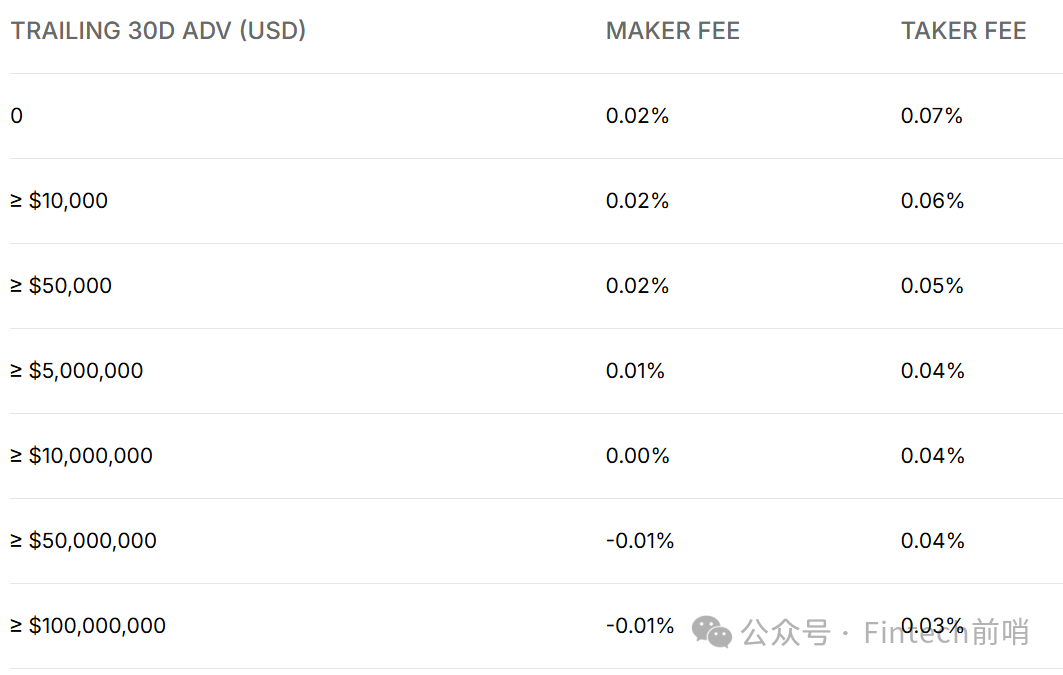
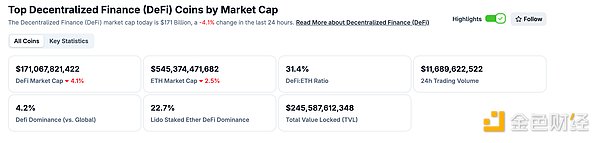



 Bitcoin
Bitcoin  Ethereum
Ethereum  Tether USDt
Tether USDt  XRP
XRP  BNB
BNB  Solana
Solana  USDC
USDC  TRON
TRON  Dogecoin
Dogecoin  Cardano
Cardano 
 行情
行情 
 平台
平台 
 首页
首页 
 观点
观点 
 快讯
快讯